Paper Collection of Safe Diffusion at ICCV 2025
ICCV 2025
Submission Deadline: 2025.03.07
Official Site:
Attack
Adversarial Attack
DIA (DDIM Inversion Attack)
DIA: The Adversarial Exposure of Deterministic Inversion in Diffusion Models
- poster
- code
扩散模型已被证明是强大的表征学习器,在多个领域展现出最佳性能。除了加速采样之外,DDIM 还能将真实图像反转回其潜在代码。此反转操作的一个直接继承应用是真实图像编辑,其中反转产生的潜在轨迹可用于编辑图像的合成。不幸的是,这种实用工具使恶意用户能够更轻松地自由合成虚假信息或深度伪造内容,从而助长了不道德、滥用以及侵犯隐私和版权内容的传播。
虽然 AdvDM 和 Photoguard 等防御性算法已被证明可以破坏这些图像的扩散过程,但它们的目标与测试时的迭代去噪轨迹之间的不一致导致了较弱的破坏性能。
在本文中,我们提出了一种 **攻击 integrated DDIM trajectory path 的 DDIM Inversion Attack (DIA)**。
我们的研究结果支持了这种有效的破坏方法,其性能超越了以往各种编辑方法的防御方法。我们相信,我们的框架和结果可以为业界和研究界提供切实可行的防御方法,以抵御人工智能的恶意使用。

ZIUM (Zero-shot Intent-aware adversarial attack on Unlearned Models)
ZIUM: Zero-Shot Intent-Aware Adversarial Attack on Unlearned Models
- poster
- video
机器学习 (MU) 会从深度学习模型中移除特定数据点或概念,以增强隐私保护并防止生成敏感内容。对抗性提示可以利用 Unlearn Models(UMs) 生成包含已移除概念的内容,从而构成重大安全风险。
然而,现有的对抗性攻击方法仍然难以生成符合攻击者意图的内容,同时识别 successful prompts 的计算成本也很高。
为了应对这些挑战,我们提出了 ZIUM (a Zero-shot Intent-aware adversarial attack on Unlearned Models) ,它能够 灵活地定制目标攻击图像 以反映攻击者的意图。此外,ZIUM 支持 Zero-shot对抗攻击,而无需针对先前攻击过的遗忘概念进行进一步优化。
在各种 MU 场景下的评估表明,ZIUM 能够 有效地根据用户意图提示成功定制内容,同时获得比现有方法更高的攻击成功率 。此外,其零样本对抗攻击 显著缩短了针对先前攻击过的未学习概念的攻击时间。

Backdoor Attack
BadVideo
BadVideo: Stealthy Backdoor Attack against Text-to-Video Generation
- poster
文本转视频 (T2V) 生成模型发展迅速,并在娱乐、教育和市场营销等领域得到了广泛应用。然而,这些模型的对抗性漏洞却鲜少被深入研究。
我们观察到,在 T2V 生成任务中,生成的视频通常包含大量文本提示中未明确指定的冗余信息,例如环境元素、次要对象和其他细节,这为恶意攻击者嵌入隐藏的有害内容提供了机会。 利用这种固有的冗余性,我们推出了 BadVideo,这是第一个专为 T2V 生成量身定制的后门攻击框架。
我们的攻击专注于通过两种关键策略设计目标对抗性输出:**(1) 时空组合,结合不同的时空特征** 来编码恶意信息; (2) 动态元素变换,通过引入冗余元素随时间的变化 来传达恶意信息。基于这些策略,攻击者的恶意目标可以 与用户的文本指令无缝集成,从而提供高度的隐蔽性。
此外,通过利用视频的时间维度,我们的攻击成功规避了主要分析单帧空间信息的传统内容审核系统。
大量实验表明, BadVideo 在保留原始语义并在干净输入上保持优异性能的同时,实现了较高的攻击成功率。 总而言之,我们的工作揭示了 T2V 模型的对抗性弱点,并提醒人们注意潜在的风险和误用。

Defence
Anomaly Detection for Adversarial and Backdoor Attacks
DADet (Diffusion Anomaly Detection)
DADet: Safeguarding Image Conditional Diffusion Models against Adversarial and Backdoor Attacks via Diffusion Anomaly Detection
- 暂无公开pdf
- poster
图像条件扩散模型虽然展现出卓越的生成能力,但在面对后门攻击和对抗攻击时却表现出极高的脆弱性。
本文定义了一种名为 扩散异常(diffusion anomaly) 的场景,即 在受到攻击的情况下,反向去噪过程的生成结果与正常结果存在显著偏差。
通过分析扩散异常的形成机制,我们揭示了 扰动如何在反向去噪过程(reverse process)中被放大并在结果中累积。基于分析,我们揭示了 发散性和同质性(divergence and homogeneity)现象,这导致扩散过程(diffusion process)显著偏离正常过程,多样性下降 。利用这两种现象,我们提出了一种名为 扩散异常检测(DADet) 的方法,可以 有效地检测后门攻击和对抗攻击 。
大量实验表明,我们的方案对后门攻击和对抗攻击均具有优异的防御性能。具体而言,对于后门攻击检测,我们的方法在包括MS COCO和CIFAR-10在内的不同数据集上获得了99%的F1分数。对于对抗样本的检测,在 MS COCO 和 Places365 数据集上分别评估的三次对抗攻击和两项不同任务中,F1 分数超过 84%。

Unlearn
TRCE (Towards Reliable Malicious Concept Erasure)
TRCE: Towards Reliable Malicious Concept Erasure in Text-to-Image Diffusion Models
- poster
- code
文本到图像扩散模型的最新进展使得生成逼真的图像成为可能,但也存在生成恶意内容(例如 NSFW 图片)的风险。为了降低风险,人们研究了概念擦除方法,以帮助模型忘记特定概念。
然而,目前的研究难以完全擦除隐含在提示(例如隐喻表达或对抗性提示)中的恶意概念,同时保留模型的正常生成能力。
为了应对这一挑战,我们的研究提出了 TRCE,它 使用两阶段概念擦除策略来在可靠擦除和知识保存之间实现有效的权衡 。
首先,TRCE 从擦除隐含在文本提示中的恶意语义开始。通过确定有效的映射目标(即 [EoT] 嵌入),我们优化了交叉注意力层,将恶意提示映射到上下文相似但概念安全的提示。 此步骤可防止模型在去噪过程中受到恶意语义的过度影响。在此基础上,考虑到扩散模型采样轨迹的确定性,TRCE 通过对比学习进一步引导早期去噪预测向安全方向发展,远离不安全方向,从而进一步避免恶意内容的生成。
最后,我们在多个恶意概念擦除基准上对 TRCE 进行了全面的评估,结果证明了其 在擦除恶意概念方面的有效性,同时更好地保留了模型原有的生成能力 。本文涵盖了模型生成的内容中可能包含攻击性内容。

SuMa (Subspace Mapping)
SuMa: A Subspace Mapping Approach for Robust and Effective Concept Erasure in Text-to-Image Diffusion Models
- poster
- video
文本到图像扩散模型的快速发展引发了人们对其可能被滥用于生成有害或未经授权内容的担忧。为了解决这些问题,人们提出了几种概念擦除方法。
然而,大多数方法都无法实现 完整性(即完全删除目标概念的能力) 和 有效性(即保持图像质量) 。虽然近期有少数技术成功实现了针对 NSFW 概念的上述目标,但没有一种技术能够处理诸如受版权保护的人物或名人等狭义概念。
消除这些狭义概念对于解决版权和法律问题至关重要。然而,由于这些概念与非目标相邻概念的距离很近,因此从扩散模型中删除它们具有挑战性,需要更精细的操作。在本文中,我们介绍了子空间映射(SuMa),这是一种新颖的方法,专门用于实现 擦除这些狭义概念的完整性和有效性。
SuMa 首先得出一个代表要消除的概念的目标子空间,然后通过将其映射到一个参考子空间,使两者之间的距离最小化,从而对其进行中和。这种映射可确保目标概念被完全消除,同时保持图像质量。
我们用 SuMa 在四项任务中进行了广泛的实验:子类消除、名人消除、艺术风格消除 和 实例消除,并将实验结果与当前最先进的方法进行了比较。我们的方法不仅在图像质量方面优于那些注重有效性的方法,而且还取得了与注重完整性的方法相当的结果。
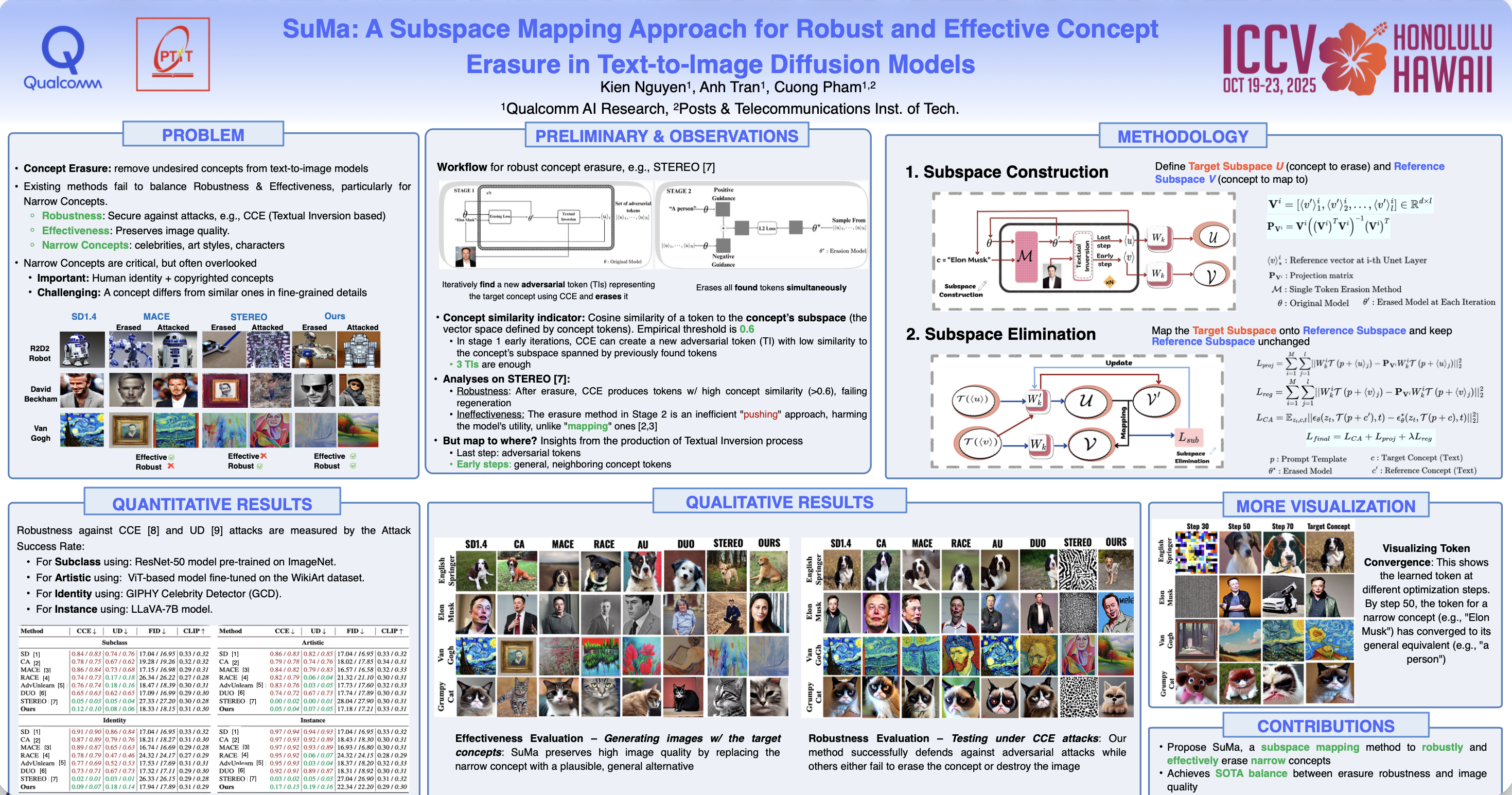
Meta-Unlearning
Meta-Unlearning on Diffusion Models: Preventing Relearning Unlearned Concepts
- poster
随着扩散模型 (DMs) 的快速发展,人们正在做出巨大努力来从预训练的 DMs 中清除有害或受版权保护的概念,以防止潜在的模型滥用。然而,据观察,即使 DMs 在发布前已正确清除,恶意的微调也会破坏这一过程,导致 DM重新学习 Unlearn的概念。
发生这种情况的部分原因是 DM 中保留的某些良性概念(例如“皮肤”)与 Unlearn的概念(例如“裸体”)相关,从而有助于通过微调进行重新学习。
为了解决这个问题,我们提出 meta-unlearning on DMs。直观地说,meta-unlearned DMs 在按原样使用时应该表现得像 unlearned DMs; 此外,如果 meta-unlearned DMs **对未学习的概念进行恶意微调时,其中保留的相关良性概念则将触发自毁(self-destruct)**,从而阻碍对 unlearned concepts 的重新学习。
我们的 meta-unlearning 框架与大多数现有的 Unlearn 方法兼容,只需添加一个易于实现的元目标(meta objective)即可。
我们通过对稳定扩散模型(SD-v1-4 和 SDXL)中的元反学习概念进行实证实验来验证我们的方法,并得到了大量消融研究的支持。
EraseBench
Erasing More Than Intended? How Concept Erasure Degrades the Generation of Non-Target Concepts
- poster
概念擦除技术因其从文本转图像模型中移除不想要概念的潜力而备受关注。虽然这些方法在受控环境中通常表现出良好的效果,但它们在实际应用中的稳健性和部署适用性仍不确定。
在本研究中,我们 (1) 发现了 评估 净化模型 的关键缺陷 ,尤其是在评估其在不同概念维度上的表现方面; (2) 系统地分析了 擦除后文本转图像模型的失效模式 。我们重点研究了概念移除对不同层次互联关系(包括视觉相似、二项式和语义相关概念)中的非目标概念造成的意外后果。
为了更全面地评估概念擦除,我们引入了 EraseBench,这是 一个多维框架,旨在严格评估擦除后的文本转图像模型 。它包含 100 多个不同的概念、精心策划的种子提示以确保可重复的图像生成,以及用于基于模型评估的专用评估提示。我们的框架 与一套强大的评估指标相结合 ,对 概念擦除的有效性及其对模型行为的长期影响 进行了全面而深入的分析。
我们的研究结果揭示了 概念纠缠现象,其中擦除导致非目标概念的意外抑制,导致溢出退化,表现为扭曲和生成质量下降。

Holistic Unlearning Benchmark
Holistic Unlearning Benchmark: A Multi-Faceted Evaluation for Text-to-Image Diffusion Model Unlearning
- poster
- webpage
随着文本到图像的传播模型获得广泛的商业应用,人们越来越担心不道德或有害的使用,包括未经授权生成受版权保护的内容或敏感内容。Concept unlearning 已成为应对这些挑战的一种有前途的解决方案,它从预训练模型中去除不需要的和有害的信息。
然而, 之前的评估主要关注是否在保留图像质量的同时删除了目标概念,而忽略了更广泛的影响,例如意想不到的副作用。
在本文中,我们提出了 Holistic Unlearning Benchmark (HUB) ,这是一个全面的框架,用于评估Unlearn方法的 6个关键维度:faithfulness, alignment, pinpoint-ness, multilingual robustness, attack robustness
我们的基准涵盖 33 个目标概念,每个概念包含 16,000 个提示 ,涵盖 4个类别:Celebrity, Style, Intellectual Property, and NSFW
我们的调查显示,没有一种方法在所有评估标准上都表现出色。通过发布我们的评估代码和数据集,我们希望激发该领域的进一步研究,从而产生更可靠、更有效的Unlearn方法。

Watermark
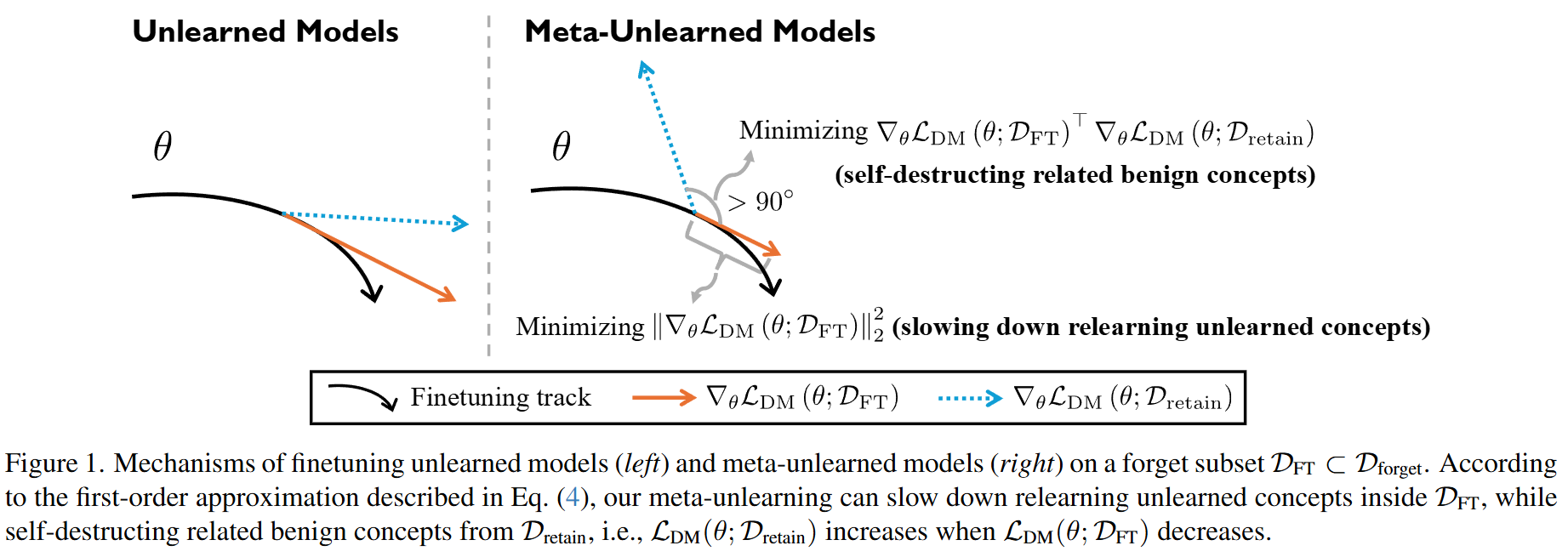
PlugMark
PlugMark: A Plug-in Zero-Watermarking Framework for Diffusion Models
- 暂无公开pdf
- poster
- video
扩散模型极大地推动了图像合成领域的发展,其知识产权 (IP) 的保护也成为至关重要的问题。
现有的 IP 保护方法主要集中在 通过改变扩散过程的结构来将水印嵌入到生成的图像中。然而,这些方法不可避免地会 损害生成图像的质量,并且特别容易受到微调攻击,尤其是对于稳定扩散 (SD) 等开源模型。
本文提出了 PlugMark,一个用于扩散模型的新型插件式零水印框架 。PlugMark 的核心思想基于 两个观察结果:分类器可以通过其决策边界唯一地表征,扩散模型可以通过从训练数据中获得的知识唯一地表示。 在此基础上,我们引入了一个扩散知识提取器,它可以插入到扩散模型中以提取其知识并输出分类结果。 随后,PlugMark 基于该分类结果生成边界表示,作为零失真水印,唯一地表示决策边界,进而表示扩散模型的知识。由于只有提取器需要训练,因此原始扩散模型的性能不受影响。
大量实验结果表明,PlugMark 可以从原始模型及其后处理版本中稳健地提取高置信度零水印,同时有效地将它们与非后处理的扩散模型区分开来。
Copyright
CopyrightShield
CopyrightShield: Enhancing Diffusion Model Security Against Copyright Infringement Attacks
- poster
扩散模型因其在图像合成等领域卓越的数据生成能力而备受关注。然而,近期研究表明,扩散模型易受版权侵权攻击。 攻击者会将经过策略性修改的非侵权图像注入训练集,诱导模型在特定“毒害”字幕的提示下生成侵权内容。
针对此问题,我们首先提出了一个防御框架—— CopyrightShield ,以防御上述攻击。具体而言,我们 分析了扩散模型的记忆机制,发现攻击利用模型对特定空间位置和提示的过拟合,导致其在后门触发下生成毒害样本。
基于此,我们提出了 一种基于空间掩蔽和数据归因的毒害样本检测方法,以量化毒害风险并准确识别隐藏的后门样本。 为了进一步降低对毒害特征的记忆,我们引入了 一种自适应优化策略,将动态惩罚项集成到训练损失中,在保持生成性能的同时降低对侵权特征的依赖。
实验结果表明,CopyrightShield在两种攻击场景下显著提升了中毒样本的检测性能,平均F1-scores达到0.665,首次攻击时间(FAE)延迟115.2%,版权侵权率(CIR)降低56.7%。相比于扩散模型中的SoTA后门防御,防御效果提升约25%,展现了其在提升扩散模型安全性方面的优越性和实用性。

Other
Unlearn
趋势:解决 Machine Unlearn 的两个目标的优化冲突问题
- 遗忘特定概念/数据
- 保持总体性能(减小对其他概念的干扰)
MUNBa (Machine Unlearning via Nash Bargaining)
MUNBa: Machine Unlearning via Nash Bargaining
- TL;DR: 用纳什谈判解的方法,优化MU的两个目标
- poster
机器遗忘(MU)旨在有选择性地清除模型中的有害行为,同时保留模型的整体效用。作为一个多任务学习问题,MU 需要在 遗忘特定概念/数据 和 保持总体性能 这两个目标之间取得平衡。
为了解决梯度冲突和优势问题,我们 将 MU 重新表述为双人合作博弈 ,即遗忘博弈者和保留博弈者通过梯度建议来最大化他们的整体收益并平衡他们的贡献。
我们对 MU 的表述 保证了均衡解,任何偏离最终状态的情况都会导致双方总体目标的降低,从而确保每个目标的最优性。
我们用 ResNet、视觉语言模型 CLIP 和文本到图像扩散模型进行了大量实验,结果表明我们的方法优于最先进的 MU 算法,在遗忘和保持之间实现了更好的权衡。

Water4MU
Invisible Watermarks, Visible Gains: Steering Machine Unlearning with Bi-Level Watermarking Design
- poster
随着人们对被遗忘权的需求日益增长,Machine Unlearn (MU) 已成为增强信任和法规遵从性的重要工具,因为它能够从机器学习 (ML) 模型中消除敏感数据的影响。然而,大多数 MU 算法主要依靠 in-training methods 来调整模型权重,而对 data-level adjustments 的探索有限。
为了弥补这一差距,我们提出了一种新颖的方法,利用 digital watermarking 策略性地修改数据内容,来促进 MU。 通过集成 watermarking,我们建立了 一种受控的Unlearn机制,该机制能够精确删除指定数据,同时保持不相关任务的模型效用。
我们首先研究了带水印的数据对 MU 的影响,发现 MU 可以有效地推广到带水印的数据。在此基础上,我们引入了 一个有利于反学习的水印框架,称为 Water4MU,以提高反学习的有效性。 Water4MU 的核心是 一个双层优化 (bi-level optimization, BLO) 框架:在上层,水印网络经过优化以最小化遗忘难度;而在下层,模型本身则独立于水印进行训练。
实验结果表明,Water4MU 在图像分类和图像生成任务中均能有效进行 MU。值得注意的是,它在具有挑战性的 MU 场景(即所谓的“挑战性遗忘”)中的表现优于现有方法。
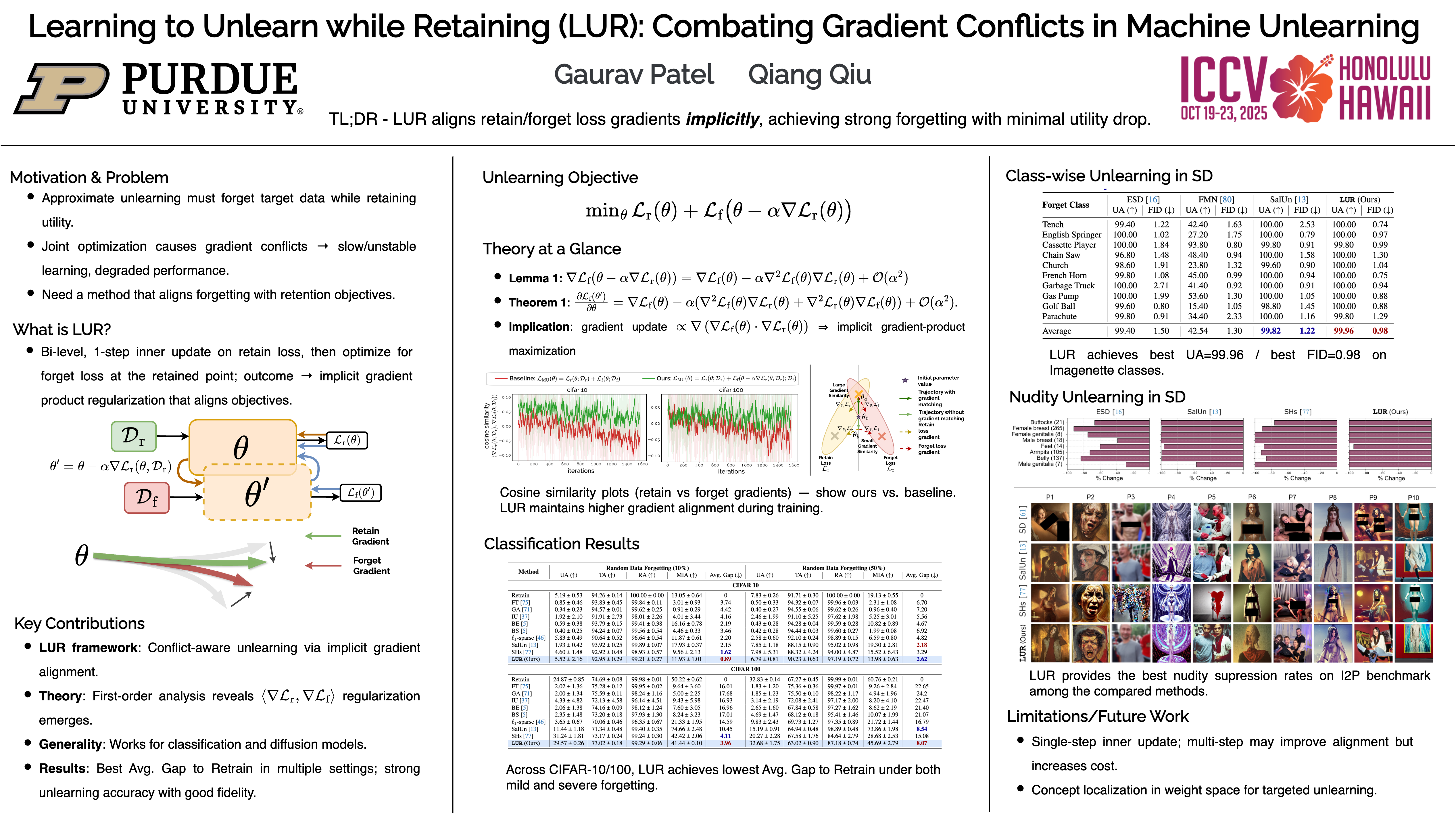
LUR (Learning to Unlearn while Retaining)
Learning to Unlearn while Retaining: Combating Gradient Conflicts in Machine Unlearning
- poster
- video
机器学习的 Unlearning 最近备受关注,其目标是选择性地移除与特定数据相关的知识,同时保留模型在剩余数据上的性能。
这一过程中的一个根本挑战是 如何平衡有效的遗忘和知识保留 ,因为对这些相互竞争的目标进行简单的优化可能会导致梯度冲突,从而阻碍收敛并降低整体性能。
为了解决这个问题,我们提出了 Learning to Unlearn while Retaining ,旨在 缓解遗忘和保留目标之间的梯度冲突。
我们的方法通过一种在所提框架内自然形成的 隐式梯度正则化机制,策略性地避免了冲突。 这可以防止遗忘和保留之间出现梯度冲突,从而实现有效的遗忘,同时保留模型的效用。
我们在判别任务和生成任务中验证了我们的方法,证明了它在不影响剩余数据性能的情况下实现Unlearn的有效性。我们的结果突出了避免此类梯度冲突的优势,优于未能考虑这些相互作用的现有方法。
FG-OrIU
FG-OrIU: Towards Better Forgetting via Feature-Gradient Orthogonality for Incremental Unlearning
- 暂无公开pdf
- poster
Incremental unlearning (IU) 对于预训练模型满足顺序数据删除要求至关重要,但现有方法主要抑制参数或混淆知识,而没有在特征和梯度层面进行明确的约束,导致 superficial forgetting(表面遗忘),残留信息仍然可恢复。
这种不完全遗忘存在安全漏洞风险,并破坏了保留平衡,尤其是在 IU 场景中。
我们提出了 FG-OrIU(Feature-Gradient Orthogonality for Incremental Unlearning) ,这是第一个 统一特征和梯度层面正交约束以实现深度遗忘的框架,其中遗忘效应是不可逆的。
FG-OrIU 通过奇异值分解 (SVD) 对特征空间进行分解,将遗忘特征和剩余类别特征分离到不同的子空间中。
然后,它强制实施双重约束:对遗忘类和剩余类进行 特征正交投影 ,而 梯度正交投影 则防止在更新过程中重新引入遗忘知识并干扰剩余类。
此外,动态子空间自适应 会合并新遗忘的子空间并收缩剩余子空间,从而确保在连续的反学习任务中,移除和保留之间保持稳定的平衡。
大量实验证明了我们方法的有效性。
- Title: Paper Collection of Safe Diffusion at ICCV 2025
- Author: LeoJeshua
- Created at : 2025-06-20 15:49:09
- Updated at : 2025-11-14 14:23:54
- Link: https://leojeshua.github.io/DMs/Paper-Collection-of-Safe-Diffusion_ICCV-2025/
- License: This work is licensed under CC BY-NC-SA 4.0.